AgentGuard: Deadlock Prevention for Multi-AI-Agent Systems via Extended Banker’s Algorithm
Saurabh Kumar
Abstract
Multi-agent systems powered by large language models (LLMs) increasingly share limited resources (API rate limits, tool slots, token budgets, and database connections) yet lack formal mechanisms to prevent deadlock. We present AgentGuard, a library that applies and extends Dijkstra’s Banker’s Algorithm to the domain of AI agent orchestration. AgentGuard provides mathematically guaranteed deadlock prevention by performing a safety check before every resource grant: if granting a request would leave the system in a state where not all agents can complete, the request is deferred. Beyond the classical algorithm, we identify and address three gaps that arise when applying the Banker’s Algorithm to LLM-based agents: (1) agents that stall silently while holding resources, addressed by a Progress Monitor with configurable stall detection and automatic resource reclamation; (2) authority deadlocks caused by circular delegation chains that involve no resource contention, addressed by a Delegation Tracker with real-time cycle detection; and (3) the inability of LLM agents to declare maximum resource needs upfront, addressed by an Adaptive Demand Estimator that learns resource patterns at runtime using statistical estimation and runs a probabilistic variant of the Banker’s Algorithm. AgentGuard is implemented as a C++17 library with Python bindings via pybind11, native LangGraph/LangChain integration, and is validated by 285 tests (189 C++ unit/integration, 96 Python). The system is open-source under the MIT license and available on PyPI as agentguard-ai.
1. Introduction
The emergence of large language model (LLM)-based autonomous agents [Xi et al., 2023, Wang et al., 2024] has given rise to multi-agent systems where multiple AI agents collaborate on complex tasks by sharing limited resources. Frameworks such as LangGraph [LangChain, Inc., 2024], LangChain [Chase, 2023], AutoGen [Wu et al., 2023], and CrewAI [Moura, 2024] enable developers to orchestrate multi-agent workflows where agents access shared APIs, execute tools, and consume token budgets.
These shared resources create the classical conditions for deadlock [Coffman et al., 1971]:
- Mutual exclusion: A code interpreter can serve only one agent at a time.
- Hold and wait: An agent holds API slots while waiting for a browser tool.
- No preemption: Resources cannot be forcibly reclaimed from an active LLM call.
- Circular wait: Agent A waits for resources held by B, while B waits for resources held by A.
When all four conditions hold simultaneously, the system deadlocks: agents freeze silently with no error and no timeout. The prevailing "solution" in existing frameworks is max_iterations--a counter that terminates agents after N steps. This is a timeout, not a prevention mechanism; it wastes tokens, time, and resources while the deadlock goes undetected.
The Banker's Algorithm, published by Dijkstra in 1965 [Dijkstra, 1965], provides a principled solution: before granting any resource request, simulate whether all agents can still complete. If the answer is no (an unsafe state), defer the request until it becomes safe. This eliminates deadlock by construction, as the system never enters a state from which deadlock is reachable.
However, applying the classical Banker's Algorithm directly to LLM agents reveals three fundamental gaps:
Gap 1: Silent stalls. An LLM agent may enter an infinite reasoning loop or hang on a tool call, holding resources indefinitely. The classical algorithm assumes agents make progress toward completion; LLM agents may not.
Gap 2: Authority deadlocks. Agent A delegates a task to B, B delegates to C, and C delegates back to A. No resource is held, yet the system is completely stuck. This form of deadlock is invisible to resource-based analysis.
Gap 3: Unknown maximum demands. The Banker's Algorithm requires every process to declare its maximum resource needs upfront. An OS process can do this; an LLM agent cannot--it has no idea how many API calls a complex research task will require.
We present AgentGuard, a system that addresses all three gaps while preserving the mathematical guarantees of the Banker's Algorithm. Our contributions are:
- A complete, production-grade implementation of the Banker's Algorithm for multi-AI-agent resource management, with synchronous, asynchronous, and batch request modes.
- A Progress Monitor that detects stalled agents using named progress metrics and configurable stall thresholds, with optional automatic resource reclamation.
- A Delegation Tracker that maintains a directed graph of active agent delegations and performs real-time cycle detection using BFS and DFS algorithms.
- An Adaptive Demand Estimator that learns agent resource patterns at runtime using rolling statistics and runs a probabilistic Banker's Algorithm using estimated maximum needs computed via the inverse normal CDF.
- A high-performance C++17 implementation with Python bindings and native LangGraph integration, validated by 285 tests.
2. Background and Related Work
2.1 Deadlock Theory
The four necessary conditions for deadlock were formalized by Coffman et al. [1971]: mutual exclusion, hold and wait, no preemption, and circular wait. Strategies for handling deadlock fall into three categories: prevention (eliminate one or more conditions structurally), avoidance (deny requests that could lead to deadlock), and detection and recovery (allow deadlock to occur, then break it). The Banker's Algorithm [Dijkstra, 1965] is the canonical avoidance strategy, maintaining a safe state invariant: the system is safe if there exists an ordering in which all agents can acquire their maximum needs and complete. The algorithm runs in O(n²m) time, where n is the number of agents and m is the number of resource types [Silberschatz et al., 2018, Tanenbaum and Bos, 2014].
2.2 LLM-Based Multi-Agent Systems
The use of LLMs as autonomous agents has been surveyed extensively [Guo et al., 2024, Li et al., 2024, Wang et al., 2024, Xi et al., 2023]. Modern agent architectures employ reasoning patterns such as ReAct [Yao et al., 2023] and chain-of-thought [Wei et al., 2022], and increasingly use tools [Schick et al., 2024, Qin et al., 2024] to interact with external systems. Multi-agent frameworks like LangGraph, AutoGen, MetaGPT [Hong et al., 2024], and CrewAI orchestrate multiple such agents. Generative agents [Park et al., 2023] have demonstrated that LLM-powered agents can exhibit complex emergent behaviors, including resource contention patterns.
Despite this rapid development, none of these frameworks provide formal deadlock prevention. The standard approach is iteration limits (max_iterations), which is a timeout--not a safety mechanism.
2.3 Resource Management in LLM Serving
At the infrastructure level, systems like vLLM [Kwon et al., 2023] and Sarathi-Serve [Agrawal et al., 2024] address throughput-latency tradeoffs in LLM inference serving. Sheng et al. [2024] propose the Virtual Token Counter (VTC) for fair scheduling of LLM requests across tenants. These systems operate at the serving layer (GPU memory, KV-cache management), whereas AgentGuard operates at the agent orchestration layer (API rate limits, tool slots, token budgets)--a complementary concern.
2.4 Classical Multi-Agent Coordination
The field of multi-agent systems (MAS) has a rich history [Wooldridge, 2009, Dorri et al., 2018]. Traditional MAS research addresses coordination protocols, negotiation, and resource allocation. However, LLM-based agents differ from classical rational agents in key ways: their behavior is stochastic, their resource consumption is unpredictable, and they may delegate tasks to each other in complex patterns that create authority deadlocks invisible to resource-based analysis.
3. System Architecture
AgentGuard is designed as a modular, layered system with the following component hierarchy:
- ResourceManager (Orchestrator)
- SafetyChecker -Banker's Algorithm implementation
- RequestQueue -Priority-ordered pending requests
- SchedulingPolicy -Request prioritization strategy
- Monitor -Event sink for observability
- ProgressTracker -Gap 1: Silent stall detection
- DelegationTracker -Gap 2: Authority deadlock prevention
- DemandEstimator -Gap 3: Unknown demand estimation (feeds estimates to SafetyChecker)
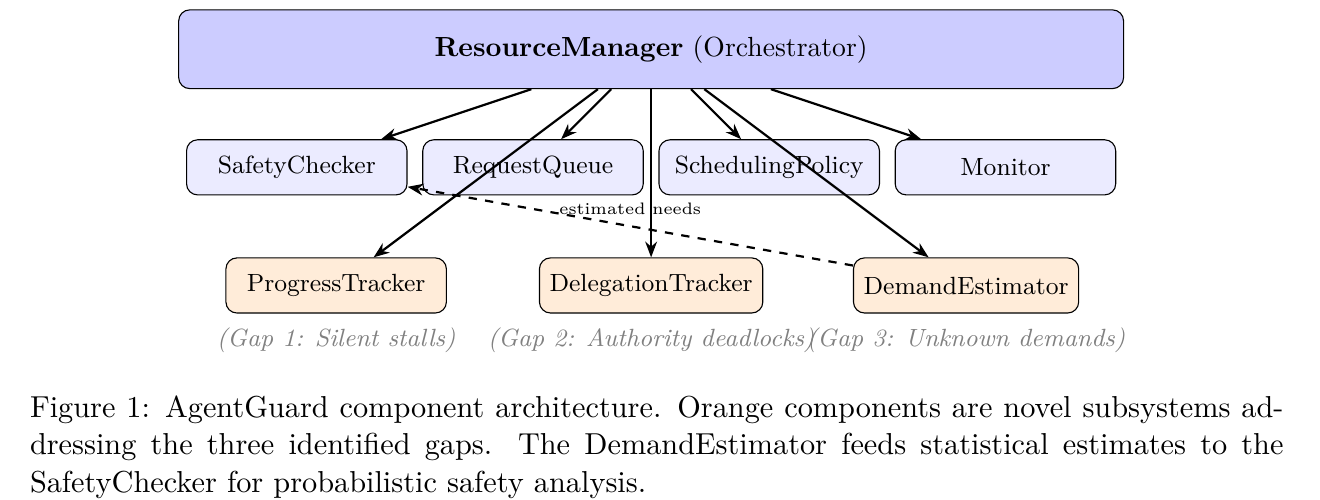
3.1 Core Components
ResourceManager. The central orchestrator that manages the lifecycle of agents and resources. It maintains the Banker's Algorithm state matrices (allocation, maximum need, available) protected by a std::shared_mutex for concurrent read access and exclusive write access.
SafetyChecker. A pure, stateless function implementing the Banker's Algorithm. Given a SafetyCheckInput (total resources, available resources, per-agent allocations, per-agent maximum needs), it returns whether the state is safe and, if so, a valid completion sequence. Being a pure function, it requires no internal locking, enabling safe parallel invocation.
RequestQueue. A priority-ordered queue of pending resource requests with timeout support. Requests are ordered by priority (descending) and submission time (FIFO within equal priority).
SchedulingPolicy. An abstract interface for request prioritization, with five built-in implementations: FIFO, Priority, ShortestNeedFirst (maximizes throughput by prioritizing agents closest to completion), DeadlineAware, and Fairness (prevents starvation).
Monitor. An event sink interface with 25 event types covering the full lifecycle of requests, safety checks, progress monitoring, delegation tracking, and adaptive demand estimation. Three built-in implementations: ConsoleMonitor (logging), MetricsMonitor (statistics collection with alert thresholds), and CompositeMonitor (fan-out).
3.2 Request Processing Pipeline
When an agent requests resources, the following pipeline executes:
- Validation: Verify agent exists, resource exists, and request does not exceed the agent's declared maximum claim.
- Demand recording: Record the request in the DemandEstimator for statistical learning.
- Availability check: If
available[r] < requested, the request cannot be granted immediately. - Safety check: Construct a hypothetical state where the request is granted and run the Banker's Algorithm. If the resulting state is unsafe, deny or defer.
- Grant or queue: If safe, allocate resources atomically. Otherwise, enqueue the request for later evaluation by the background processor.
- Background processing: A dedicated thread periodically re-evaluates queued requests as resources are released, using the configured scheduling policy to determine evaluation order.
4. Core Algorithm: Banker's Safety Check
4.1 Formalization
Let n be the number of agents and m be the number of resource types. We define:
- Total ∈ Zᵐ: total system capacity per resource type.
- Available ∈ Zᵐ: currently unallocated resources.
- Alloc ∈ Zⁿˣᵐ: current allocation matrix.
- Max ∈ Zⁿˣᵐ: maximum need matrix.
- Need = Max − Alloc: remaining need matrix.
Definition 1 (Safe State). A state (Available, Alloc, Max) is safe if there exists a permutation ⟨a₁, a₂, ..., aₙ⟩ of agents such that for each aᵢ, the remaining needs of aᵢ can be satisfied by the currently available resources plus the resources held by all agents aⱼ with j < i.
4.2 Algorithm
Algorithm 1: Banker's Algorithm Safety Check
Input: Available, Alloc, Need, agents {a₁, ..., aₙ}, resource types {r₁, ..., rₘ}
Output: (is_safe, safe_sequence)
1 Work ← Available
2 Finished ← ∅
3 Sequence ← []
4 for round ← 1 to n do
5 found ← false
6 foreach agent aᵢ ∉ Finished do
7 if Need[aᵢ][r] ≤ Work[r] for all r then
8 Work[r] ← Work[r] + Alloc[aᵢ][r] for all r
9 Finished ← Finished ∪ {aᵢ}
10 Sequence.append(aᵢ)
11 found ← true
12 end
13 end
14 if ¬found then
15 if |Finished| = n then break // All agents finished
16 else return (false, ∅) // Unsafe state
17 end
18 end
19 return (true, Sequence)
Complexity. The outer loop runs at most n times. The inner loop iterates over up to n agents, and for each, checks m resource types. Total: O(n²m).
Multi-finish correction. A subtle bug arises when multiple agents become finishable in a single round: subsequent rounds may find no new agents to process. Our implementation checks whether |Finished| = n before reporting an unsafe state (line 15), preventing false negatives.
4.3 Hypothetical and Batch Checks
For each incoming request, AgentGuard constructs a hypothetical state where the request is granted:
- Available'[r] = Available[r] − q
- Alloc'[a][r] = Alloc[a][r] + q
where a is the requesting agent, r is the resource type, and q is the requested quantity. The safety check is then run on the hypothetical state. Batch requests follow the same pattern, applying all requests atomically before checking safety.
5. Extension 1: Progress Monitor
5.1 Motivation
The Banker's Algorithm assumes that once an agent is granted its maximum resources, it will eventually complete and release them. LLM agents violate this assumption: an agent may enter an infinite reasoning loop, a tool call may hang, or the LLM may produce degenerate outputs indefinitely. When a stalled agent holds resources, all other agents that need those resources are blocked, leading to a livelock that is observationally identical to deadlock.
5.2 Design
The Progress Monitor maintains a ProgressRecord for each registered agent:
ProgressRecord = {
metrics: Map(string → R),
last_update: Timestamp,
stall_threshold: Duration
}
Agents report progress via report_progress(agent_id, metric, value), which updates the metric and resets the timestamp. A background thread periodically checks for stalls:
- is_stalled(a) = true if t_now − t_last_update(a) > θ(a)
- is_stalled(a) = false otherwise
where θ(a) is the per-agent stall threshold (with a configurable system-wide default, typically 120 seconds).
5.3 Stall Actions
When an agent is detected as stalled, the system can:
- Emit an event: Notify monitors (always).
- Auto-release resources: If
auto_release_on_stallis enabled, invoke a callback that releases all resources held by the stalled agent, unblocking other agents.
This transforms a potential livelock into a recoverable situation: the stalled agent's resources become available, and other agents can proceed.
6. Extension 2: Delegation Tracker
6.1 Motivation
LLM agents frequently delegate tasks to other agents. When Agent A delegates to B, B to C, and C back to A, a circular delegation chain forms. No resource is held, no tool is blocked, and no existing framework detects this. Yet the system is completely frozen--each agent is waiting for a response from the next agent in the cycle.
We term this an authority deadlock: a deadlock that arises from the delegation structure rather than resource contention. It satisfies a delegation-domain analogue of the four Coffman conditions: each delegation is exclusive (one-to-one), agents hold their pending delegations while waiting for results, delegations cannot be preempted, and the delegation chain forms a cycle.
6.2 Design
The Delegation Tracker maintains a directed graph G = (V, E) where vertices are agents and edges represent active delegations.
Data structure. An adjacency list adj: V → 2ᵛ and an edge metadata map edges: (V × V) → DelegationInfo.
Cycle detection. Two algorithms are employed:
- Incremental (after-add): When edge (u, v) is added, run BFS from v to check if there exists a path back to u. Complexity: O(|V| + |E|).
- Full-graph: DFS with three-color marking (White/Gray/Black) [Cormen et al., 2022], using an explicit stack to avoid recursion limits. A back edge (to a Gray node) indicates a cycle. Complexity: O(|V| + |E|).
6.3 Cycle Response Policies
When a cycle is detected, the system supports three configurable actions:
- NotifyOnly: Emit an event but accept the delegation (for monitoring).
- RejectDelegation: Refuse the cycle-creating delegation.
- CancelLatest: Add then immediately remove the edge (log the attempt).
The RejectDelegation policy provides a strict guarantee: the delegation graph is always a DAG, making authority deadlock impossible by construction (analogous to how the Banker's Algorithm makes resource deadlock impossible).
7. Extension 3: Adaptive Demand Estimator
7.1 Motivation
The Banker's Algorithm requires each agent to declare its maximum resource needs a priori. For OS processes, this is feasible: a database connection pool declares its maximum connections at startup. For LLM agents, it is not: the number of API calls required to research a topic, the number of tool invocations needed to debug code, or the number of tokens consumed by a reasoning chain are all unknown at task assignment time.
Over-declaring maximum needs is safe but conservative: the Banker's Algorithm may deny requests that would, in practice, be safe. Under-declaring is unsafe: it violates the algorithm's invariant and re-introduces deadlock risk.
7.2 Statistical Estimation
The Demand Estimator observes resource requests at runtime and maintains rolling statistics per (agent, resource) pair:
UsageStats = { n, Σxᵢ, Σxᵢ², max(xᵢ), max(cumulativeᵢ) }
with a circular buffer of size W (configurable, default 50) for windowed statistics. The sample mean and variance are:
- μ̂ = (1/n) Σxᵢ
- σ̂² = (1/(n−1)) (Σxᵢ² − (Σxᵢ)²/n)
The estimated maximum need at confidence level α is:
Max̂(a, r, α) = ⌈ max(μ̂ + kα · σ̂, max(xᵢ)) ⌉
where kα = Φ⁻¹(α) is the α-quantile of the standard normal distribution, computed via the Beasley-Springer-Moro rational approximation [Beasley and Springer, 1977, Moro, 1995].
7.3 Cold-Start Handling
With zero observations, the estimator returns a configurable default demand. With a single observation, it applies a headroom factor (default 2×) to the observed value. The general case activates with n ≥ 2 observations.
7.4 Demand Modes
Each agent operates in one of three modes:
- Static (default): Use only explicit
declare_max_need()declarations. Backward-compatible with the classical algorithm. - Adaptive: Use only statistical estimates. No upfront declaration required.
- Hybrid: Use min(declared, estimated). Statistical estimates are capped by the explicit declaration, providing a safety bound.
7.5 Probabilistic Safety Check
For agents in Adaptive or Hybrid mode, the ResourceManager constructs a modified safety check input where max_need values come from the DemandEstimator rather than static declarations. The standard Banker's Algorithm then runs on (Available, Alloc, Max'). The result is annotated with the confidence level and the estimated maximum needs used.
Higher confidence levels produce larger estimates, which makes the safety check more conservative. The default confidence level is 0.95.
8. Implementation
8.1 C++ Core
AgentGuard is implemented in C++17 (approximately 4,700 lines of code across 33 source files). Key implementation decisions include:
Thread safety. The core state is protected by std::shared_mutex [Williams, 2019], allowing multiple concurrent readers (safety checks, snapshot queries) with exclusive writes (allocations, releases). The SafetyChecker is a pure function with no internal state, requiring no synchronization. The ProgressTracker and DelegationTracker each have independent std::mutex instances to minimize contention.
Background processor. A dedicated thread (process_queue_loop) re-evaluates pending requests when resources are released, using std::condition_variable_any for efficient wakeup. The polling interval is configurable (default 10ms).
Quick-fail optimization. When the safety check fails but resources are physically available, if no background processor is running, the request is denied immediately rather than waiting until timeout--the system state will not change without external intervention.
8.2 Python Bindings
Python bindings are provided via pybind11 [Jakob et al., 2017], exposing the complete C++ API. Key considerations:
GIL management. Blocking calls (resource requests with timeout) release the GIL to allow other Python threads to execute. The GIL is re-acquired for Python callbacks (monitor events, stall actions).
LangGraph integration. A high-level Python layer provides:
- AgentGuard wrapper: String-based resource names mapped to integer IDs, context managers for acquire/release.
@guarded_tooldecorator: Wraps any function with automatic resource acquisition and release, including exception cleanup.GuardedToolNode: Drop-in replacement for LangGraph'sToolNodewith automatic resource management per tool.AgentGuardCallbackHandler: LangChain callback handler that instruments tool calls with resource management.
8.3 Resource Taxonomy
AgentGuard provides AI-specific resource types:
| Resource Type | Description |
|---|---|
| ApiRateLimit | Requests per time window (e.g., 60 OpenAI calls/minute) |
| TokenBudget | Token consumption with configurable input/output ratios |
| ToolSlot | Exclusive or shared access to tools (code interpreter, browser) |
| MemoryPool | Memory allocation with configurable units and eviction policies |
| DatabaseConn | Connection pool management |
| GpuCompute | GPU resource allocation |
9. Evaluation
9.1 Test Suite
AgentGuard is validated by 285 tests: 189 C++ tests (unit and integration) and 96 Python tests.
| Category | Focus | Tests |
|---|---|---|
| C++ Unit Tests | ||
| Safety Checker | Banker's algorithm correctness | 28 |
| Resource Manager | Request lifecycle, agent management | 24 |
| Request Queue | Priority ordering, timeout expiration | 15 |
| Agent & Resource | State transitions, allocation tracking | 18 |
| Progress Tracker | Stall detection, progress reporting | 14 |
| Delegation Tracker | Cycle detection (BFS, DFS) | 18 |
| Demand Estimator | Statistical estimation, cold-start | 16 |
| Probabilistic Safety | Banker's with estimated demands | 12 |
| C++ Integration Tests | ||
| Deadlock Prevention | Dining Philosophers, circular wait | 12 |
| Concurrent Agents | Multi-threaded stress testing | 10 |
| Progress Monitor | End-to-end stall detection | 8 |
| Delegation Cycles | Real delegation chain scenarios | 8 |
| Adaptive Demands | Runtime estimation validation | 6 |
| Python Tests | ||
| Binding Correctness | Enums, structs, exceptions | 31 |
| Manager Bindings | ResourceManager lifecycle | 17 |
| Threading | GIL release, concurrent access | 7 |
| Monitors | Python subclassing, composite | 8 |
| Subsystems | SafetyChecker, DemandEstimator | 13 |
| LangGraph Guard | AgentGuard wrapper | 14 |
| LangGraph Decorator | @guarded_tool | 6 |
| Total | 285 |
9.2 Deadlock Prevention Proof
The integration test suite includes classical deadlock scenarios that are guaranteed to deadlock without prevention:
Dining Philosophers. Five agents, five resources (capacity 1 each). Each agent needs two adjacent resources. Without deadlock prevention, this configuration deadlocks when all agents simultaneously acquire one resource each. With AgentGuard, all five agents complete successfully--the Banker's Algorithm defers requests that would create an unsafe state, ensuring at least one agent can always proceed.
Circular Wait. Three agents forming a circular resource dependency chain (A → B → C → A). All three complete with AgentGuard.
9.3 Complexity Analysis
| Operation | Complexity | Notes |
|---|---|---|
| Safety check | O(n²m) | Banker's Algorithm |
| Hypothetical check | O(n²m) | Copy state + safety check |
| Request grant | O(n²m) | Dominated by safety check |
| Agent registration | O(1) | ID allocation |
| Cycle detection (incremental) | O(n + E) | BFS from target |
| Cycle detection (full graph) | O(n + E) | DFS with coloring |
| Demand estimation | O(1) | Pre-computed rolling statistics |
| Stall detection scan | O(n) | Check all agents |
| Queue operations | O(Q log Q) | Sort after insert |
For typical multi-agent systems (n < 100 agents, m < 50 resource types), the safety check executes in microseconds on modern hardware. The O(n²m) complexity becomes relevant only for very large systems (n > 1000), which is uncommon in current LLM agent deployments.
10. Usage Example
from agentguard.langgraph import AgentGuard, guarded_tool
# Create guard and register shared resources
guard = AgentGuard()
guard.add_resource("openai_api", capacity=60,
category="api_rate_limit")
guard.add_resource("browser", capacity=1,
category="tool_slot")
# Register agents with maximum resource needs
researcher = guard.register_agent("researcher",
max_needs={"openai_api": 10, "browser": 1})
summarizer = guard.register_agent("summarizer",
max_needs={"openai_api": 5})
fact_checker = guard.register_agent("fact_checker",
max_needs={"openai_api": 8, "browser": 1})
# Decorate tools with resource requirements
@guarded_tool(guard, researcher,
{"openai_api": 2, "browser": 1})
def research(query: str) -> str:
# Resources acquired before execution,
# released after return or exception
return call_api(query) + browse(query)
@guarded_tool(guard, summarizer, "openai_api")
def summarize(text: str) -> str:
return call_api(f"Summarize: {text}")
11. Discussion
11.1 Guarantees and Limitations
Deadlock freedom. AgentGuard provides a mathematical guarantee: if agents correctly declare (or the system correctly estimates) maximum needs, the system will never enter a deadlocked state. This guarantee holds for resource deadlocks (via the Banker's Algorithm) and authority deadlocks (via the Delegation Tracker with RejectDelegation policy).
Liveness. The Banker's Algorithm guarantees freedom from deadlock but does not guarantee freedom from starvation. The Fairness scheduling policy mitigates starvation by prioritizing long-waiting requests, and the starvation threshold configuration enables alerts.
Over-estimation cost. When maximum needs are over-declared, the Banker's Algorithm becomes more conservative, potentially denying requests that would be safe in practice. The Adaptive and Hybrid demand modes reduce this cost by using tighter, statistically-derived estimates.
Cold-start period. The Demand Estimator requires at least two observations per (agent, resource) pair before producing reliable estimates. During the cold-start period, conservative defaults are used (configurable headroom factor).
11.2 Comparison with Existing Approaches
| Approach | Prevents Deadlock | Detects Stalls | Authority Deadlock | Adaptive Demands |
|---|---|---|---|---|
| max_iterations | No | No | No | No |
| Simple timeout | No | Partial | No | No |
| Resource ordering | Partial | No | No | No |
| Classical Banker's | Yes | No | No | No |
| AgentGuard | Yes | Yes | Yes | Yes |
11.3 Applicability Beyond LLM Agents
While designed for LLM agent systems, AgentGuard's architecture is general-purpose. Any system where multiple concurrent entities share limited resources and can benefit from deadlock prevention can use AgentGuard: microservice orchestrators, robot swarm coordination, game AI resource management, and workflow engines.
12. Future Work
- Distributed Banker's Algorithm: Extend safety checks across multiple machines for large-scale agent deployments.
- ML-based demand prediction: Replace statistical estimation with learned models (e.g., time-series forecasting) for better cold-start behavior and non-stationary workloads.
- Resource preemption: Implement safe preemption protocols for LLM agents, leveraging checkpoint/resume capabilities of modern inference engines.
- Formal verification: Apply model checking tools (e.g., TLA+, SPIN) to formally verify the deadlock-freedom property of the implementation.
- Dynamic resource discovery: Automatically detect shared resources in agent frameworks without manual registration.
- Benchmarking: Develop standardized multi-agent deadlock benchmarks and measure AgentGuard's overhead under realistic LLM workloads.
13. Conclusion
We presented AgentGuard, a library that brings formal deadlock prevention to multi-AI-agent systems. By extending Dijkstra's 60-year-old Banker's Algorithm with three novel subsystems--Progress Monitor, Delegation Tracker, and Adaptive Demand Estimator--AgentGuard addresses the unique challenges of LLM-based agents: silent stalls, authority deadlocks, and unknown resource demands. The system is implemented as a high-performance C++17 library with Python bindings and LangGraph integration, validated by 285 tests, and available as open-source software.
The fundamental insight is that multi-agent AI systems face the same concurrency challenges that operating systems solved decades ago, but with new twists that require new solutions. AgentGuard demonstrates that these classical algorithms, when properly extended, can provide mathematical guarantees of correctness in modern AI systems--replacing hopeful timeouts with provable safety.
Acknowledgments
AgentGuard is open-source under the MIT license. Source code, documentation, and installation instructions are available at github.com/100rabhkr/AgentGuard. The package is available on PyPI as agentguard-ai.
References
- Agrawal, A., et al. "Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve." OSDI 2024.
- Beasley, J. D. and Springer, S. G. "Algorithm AS 111: The percentage points of the normal distribution." JRSS Series C, 26(1):118-121, 1977.
- Chase, H. "LangChain: Building applications with LLMs through composability." 2023.
- Coffman, E. G., Elphick, M. J., and Shoshani, A. "System deadlocks." ACM Computing Surveys, 3(2):67-78, 1971.
- Cormen, T. H., et al. Introduction to Algorithms. MIT Press, 4th edition, 2022.
- Dijkstra, E. W. "Cooperating sequential processes." Technical Report EWD-123, 1965.
- Dorri, A., Kanhere, S. S., and Jurdak, R. "Multi-agent systems: A survey." IEEE Access, 6:28573-28593, 2018.
- Guo, T., et al. "Large language model based multi-agents: A survey of progress and challenges." IJCAI 2024.
- Hong, S., et al. "MetaGPT: Meta programming for a multi-agent collaborative framework." ICLR 2024.
- Jakob, W., Rhinelander, J., and Moldovan, D. "pybind11 -seamless operability between C++11 and Python." 2017.
- Kwon, W., et al. "Efficient memory management for large language model serving with PagedAttention." SOSP 2023.
- LangChain, Inc. "LangGraph: Build stateful multi-actor applications with LLMs." 2024.
- Li, X., et al. "A survey on LLM-based multi-agent systems: Workflow, infrastructure, and challenges." Vicinagearth, 1(9), 2024.
- Moro, B. "The full Monte." Risk, 8(2):57-58, 1995.
- Moura, J. "CrewAI: Framework for orchestrating role-playing, autonomous AI agents." 2024.
- Park, J. S., et al. "Generative agents: Interactive simulacra of human behavior." UIST 2023.
- Qin, Y., et al. "ToolLLM: Facilitating large language models to master 16000+ real-world APIs." ICLR 2024.
- Schick, T., et al. "Toolformer: Language models can teach themselves to use tools." NeurIPS 2024.
- Sheng, Y., et al. "Fairness in serving large language models." OSDI 2024.
- Silberschatz, A., Galvin, P. B., and Gagne, G. Operating System Concepts. Wiley, 10th edition, 2018.
- Tanenbaum, A. S. and Bos, H. Modern Operating Systems. Pearson, 4th edition, 2014.
- Wang, L., et al. "A survey on large language model based autonomous agents." Frontiers of Computer Science, 18(6):186345, 2024.
- Wei, J., et al. "Chain-of-thought prompting elicits reasoning in large language models." NeurIPS 2022.
- Williams, A. C++ Concurrency in Action. Manning Publications, 2nd edition, 2019.
- Wooldridge, M. An Introduction to MultiAgent Systems. 2009.
- Wu, Q., et al. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation." 2023.
- Xi, Z., et al. "The rise and potential of large language model based agents: A survey." 2023.
- Yao, S., et al. "ReAct: Synergizing reasoning and acting in language models." ICLR 2023.